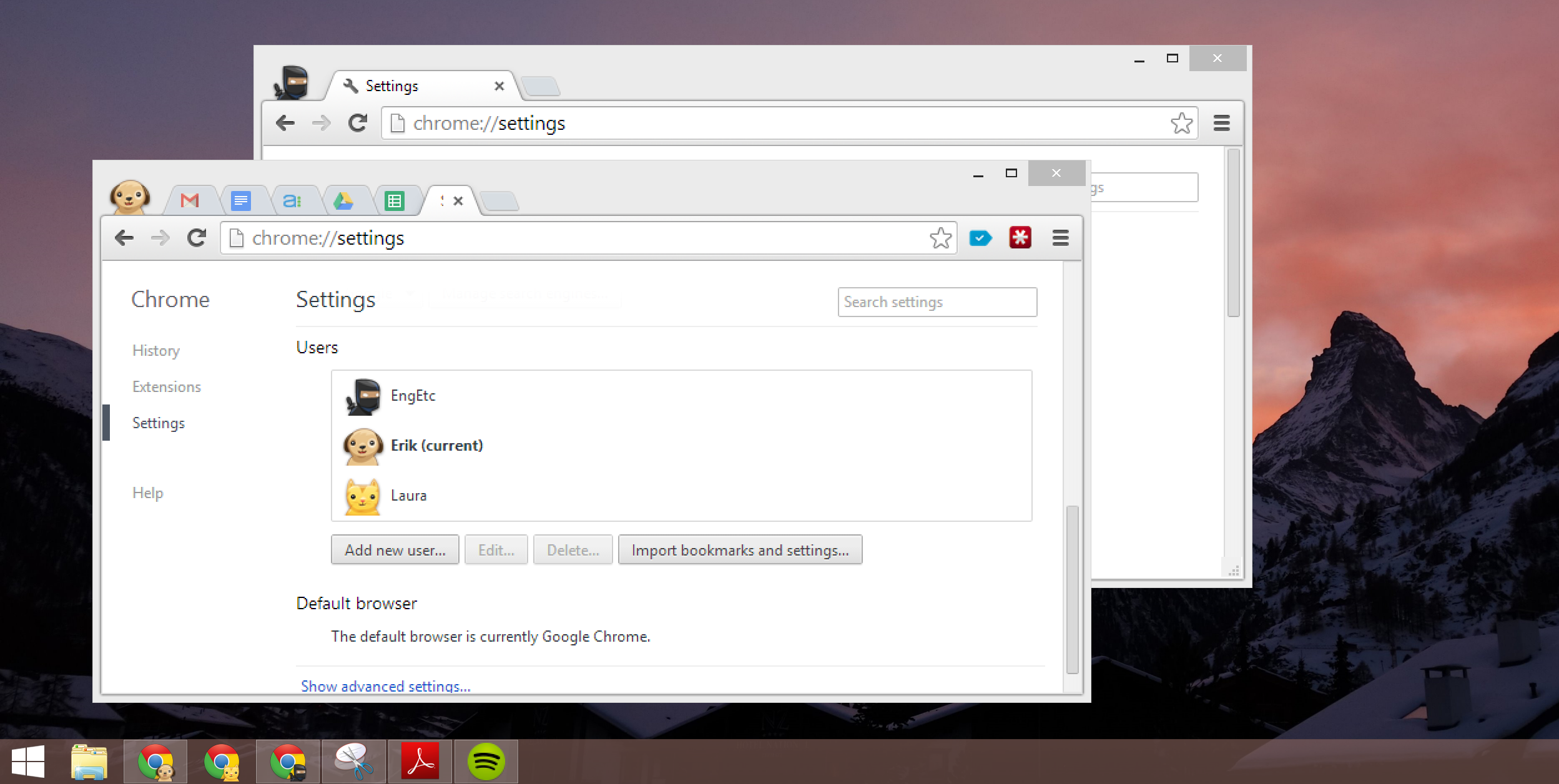
If you use Google Apps both personally and professionally, you should set up a distinct Chrome user for each context. It works much, much better than having multiple Google accounts authenticated within the same browser instance.
The Problem
Although Google supports being simultaneously logged in with Google accounts, the UI for switching between authenticated users in many services isn’t graceful. You go to gmail.com, often find yourself in your personal account, and need 2-3 clicks to switch it to your professional account . Even once you’ve done this for Gmail, opening a link to a Google doc might open Google docs in the other context – and even give you a permissions error that your personal account can’t open that document.
The easiest solution was to log into only one account at a time and to minimize switching between your personal and professional contexts. That’s probably a good habit for other reasons as well, and was mostly what I did during years of formal employment.
However, a couple years ago, when I activated two factor authentication on all my accounts (which I highly recommend), logging in and out several times a day became a much larger hassle. For the last few months, I haven’t been formally employed, so I’ve been switching in and out of professional and personal contexts even more frequently.
The Solution
Google Chrome supports multiple users. For years, my wife and I used these on shared devices to separate our accounts. I hadn’t before thought to use them to separate my own accounts into multiple users.
I set-up multiple Chrome users — one for my personal Google account and another for my professional Google Apps account. Handily, Chrome visually distinguishes users with an avatar, shown in the upper left of any browser window. Clicking the avatar allows you to launch a new browser window in the context of another user, which is simpler and more consistent than how this is implemented within individual Google web apps.
Some Windows specific stuff:
- multiple browser windows for the same user stack separately on the taskbar, with the avatar overlaid on the Chrome icon
- you can create shortcuts that directly launch Chrome in a user context
- pin to the shortcuts to the taskbar by dragging them there; pinning an active browser window will pin the Chrome application, which won’t necessarily launch in the user that was active when you pinned it
More Benefits
Clear Visual Distinction between Work and Play
Once I adjusted my bookmarks bar, extensions, and user avatar for each context, I found that the browser windows look visually quite distinct. Mentally, I think this can only help focus and avoid procrastination. My personal email is no longer just one click away, staring at me. It’s less likely that when I get stuck on coding problem for a moment, or otherwise distracted, I’ll reflexively click into my email, find something new, and turn a 30 second distraction into 5-10 minutes.
Separate Sets of Bookmarks
I used to mix personal and professional bookmarks into one bookmarks bar, which I sync’d between Chrome installations on different devices. Once you have distinct Chrome users for each account, you can have a set of professional bookmarks and a set of personal ones. It provides more toolbar real estate than you could otherwise allocate to each context.
Limit Extensions by Context
Again, this is useful in supporting a strong mental separation of your work vs personal context. But it’s also a security issue. A lot of Chrome extensions have permissions to see and access every webpage you open. Why show them more than you need? If some extensions are only relevant in one context or the other, keep them there. At very least, you’ll minimize the potential scope of private data that a malicious/invasive extension will see.